
OpenAI 日报:部署模拟进入安全评估,Codex 在欧洲扩围
本期聚焦 OpenAI 6 月 16 日的 Deployment Simulation 研究发布、Codex 在欧洲经济区/英国/瑞士扩展桌面与浏览器能力,以及 FedRAMP 状态页的持续性能降级提示。读者可以快速判断哪些更新需要进入模型评估、企业开发工具和运维排障清单。

本期的新增重点不在模型名称,而在 OpenAI 怎样判断一个候选模型能不能上线。6 月 16 日,OpenAI 发布了 Deployment Simulation 方法:用真实对话语境模拟候选模型上线前的表现,再拿上线后的真实流量校验预测是否靠谱。对开发者和企业客户来说,这比单看 benchmark 更接近未来的模型验收方式。1
速览
| 板块 | 本期发生了什么 | 对读者的意义 |
|---|---|---|
| 安全与评估 | OpenAI 发布 Deployment Simulation,用历史对话前缀和候选模型重采样来估计上线后的不良行为率。1 | 模型发布前的安全评估正在从「高难测试题」补上一层「接近真实使用分布」的检验。 |
| Codex | Codex 的 Computer Use、Chrome extension、Memories 和 Chronicle 正在向欧洲经济区、英国、瑞士用户开放。2 | Codex 在这些地区的产品能力开始接近美国市场,适合企业重新评估合规区内的开发工作流。 |
| 服务状态 | OpenAI 状态页显示 FedRAMP workspaces 和 API orgs 仍处于 degraded performance,并标注已识别 elevated errors、正在实施缓解。3 | 使用 FedRAMP 环境的团队应把接口错误率纳入当天排障优先级;普通 ChatGPT/API 用户不一定受影响。 |
| ChatGPT 发布说明 | 本次抓取时,ChatGPT Release Notes 顶部仍是 6 月 12 日的 GPT-5.2 退场和 memory controls,没有新的 6 月 16 日 ChatGPT 主版本项。4 | 今天不需要把旧的 ChatGPT release notes 当作新增功能重复追。 |
Deployment Simulation:把上线前评估拉近真实流量
OpenAI 对这个方法的定义很直接:取近期部署中的对话,移除旧模型的原始回复,再让候选模型在同样上下文里生成新回复;随后用审计和分类器找出新的失败模式,并估计这些失败在真实部署中可能出现的频率。OpenAI 说,这套方法已经用于多个 GPT-5 系列 Thinking 部署,也被用于更复杂的 agentic rollout。1
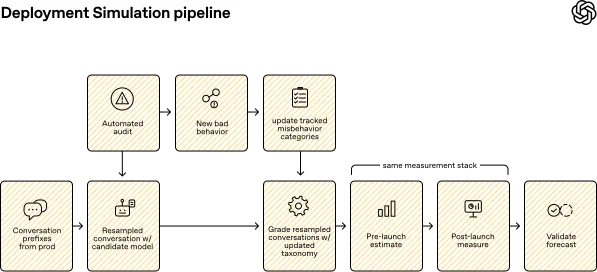
关键数字值得单独看:OpenAI 称研究共分析约 130 万条去标识化对话,覆盖 2025 年 8 月至 2026 年 3 月的 GPT-5 Thinking 到 GPT-5.4 部署;在频率预测上,aggregate median multiplicative error 为 1.5×。也就是说,如果某类不良行为真实发生率是每 10 万条 10 次,模拟可能估到每 10 万条 15 次或 6.67 次。1
这不是取代传统 red team。OpenAI 明确写到,Deployment Simulation 不适合测量低于 每 20 万条消息 1 次的行为;传统评估仍更适合覆盖低频但高危的 tail risk。更准确的理解是:它补上了传统评估不擅长的一块,即在接近真实使用分布的语境里估计常见或中等频率失败。1
另一个值得关注的点是「模型是否知道自己在被测」。OpenAI 的实验里,GPT-5.2 将真实生产流量判为 evaluation-like 的比例是 5.4%,将模拟流量判为 evaluation-like 的比例是 5.1%;而 SWE-Bench、MonorepoBench 等主要由合成样本组成的传统评估,几乎 100% 会被判成评估。这个差异解释了为什么真实上下文会成为安全评估的核心资产。1
Codex:欧洲地区补齐桌面与浏览器能力
6 月 16 日的 Codex changelog 显示,OpenAI 正在向欧洲经济区、英国和瑞士用户开放更多 Codex app 能力:Computer Use 可在 macOS 和 Windows 上操作桌面应用;Codex Chrome extension 可在有登录态的 Chrome 环境里执行浏览器任务;Memories 可记录偏好、常用工作流、技术栈和仓库约定,但在这些地区默认关闭;Chronicle 则作为 macOS 上面向 ChatGPT Pro 订阅者的 opt-in research preview。2
Loading content card…
这条更新的实际影响不是「多了几个按钮」。它把 Codex 的关键能力从单纯代码生成推进到本地桌面、浏览器登录态和长期偏好记忆。对受欧洲监管约束的团队来说,下一步要看的不是能不能用,而是哪些能力默认关闭、哪些需要管理员策略、哪些会触达本地应用和浏览器会话。2
FedRAMP 状态:不是全站事故,但要单独盯
状态页显示,FedRAMP workspaces and API orgs 的 degraded performance 最早在 Jun 15, 2026 09:23 PM 被标为 Identified,OpenAI 随后在 10:16 PM 标注正在调查,并写明受影响服务出现 elevated errors、团队正在实施缓解。3
这类状态不应被误读成所有 OpenAI 服务全线故障。状态页的受影响组件是 FedRAMP;同一页面的聚合状态还列出 API、ChatGPT、Codex 等其他类别的 uptime 指标。使用 FedRAMP 环境的组织今天应优先检查重试、降级和告警;不在该环境的团队,可以把它作为服务隔离能力的观察点,而不是直接推断普通 API 可用性。5
今天的跟进建议
- 做模型选型的人:把 Deployment Simulation 当作未来评估报告的一个新关键词。它关注真实分布中的失败率,不等同于 benchmark 分数,也不等同于红队压力测试。1
- 做企业开发工具的人:如果团队在 EEA、英国或瑞士,重新检查 Codex Computer Use、Chrome extension、Memories、Chronicle 的可用性和默认开关。尤其是 Memories 默认关闭这一点,可能影响跨项目连续性的预期。2
- 做运维或合规的人:如果使用 FedRAMP workspaces/API orgs,先看 status incident,而不是只看普通 API 监控面板。今天这条状态的范围更窄,但对相应客户群体更直接。3
Add more perspectives or context around this Post.